
Em tempos de coronavírus, todos sabem que a melhor prevenção é ficar em casa. Porém isso não significa que o PET Computação está parado.
Algumas atividades que podem ser executadas à distância continuam a todo vapor! Por isso, trazemos nesse post um assunto muito legal que é o machine learning e um trabalho muito importante que estamos desenvolvendo.
Neste artigo vamos abordar dois assuntos:
- O que é Machine Learning;
- O trabalho do PET na Pandemia de Coronavírus.
O que é Machine Learning?
Se você é aluno de Ciência da Computação ou áreas afins, provavelmente já deve ter ouvido falar em Machine Learning. Caso contrário, machine learning, ou no bom e velho português, aprendizado de máquina, nada mais é do que a capacidade de máquinas aprenderem e se aprimorarem automaticamente a partir de experiência prévia sem serem explicitamente programados.
Esse aprendizado se concentra no desenvolvimento de programas de computador que podem acessar dados e usá-los para aprender por si mesmos.
Como é feito o aprendizado de máquina?
Trabalhando com dados em um banco de dados, algoritmos irão analisá-los e serão capazes de encontrar padrões e estabelecer relações entre eles.
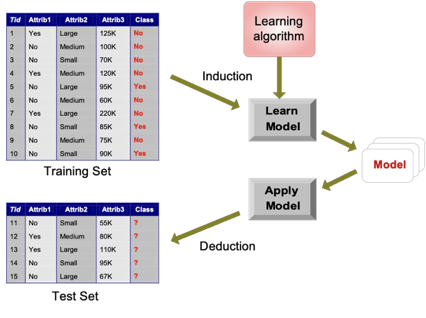
Normalmente selecionamos parte do nosso conjunto de dados e utilizamos como um treinamento. O algoritimo então irá construir um modelo de aprendizado, e para validá-lo, usamos o restante dos dados como teste.
Dessa maneira, toda vez que um novo dado é incluido no banco, a máquina vai utilizar o que aprendeu anteriormente e irá tratá-lo relacionando-o com dados parecidos.
Há diversas abordagens de como é feito esse aprendizado. No Wikipédia você pode encontrar algumas delas. As principais, que podemos citar, são os algoritmos supervisionados e os não supervisionados.
Como o próprio nome sugere, algoritmo supervisionado requer a participação humana no controle do fluxo de dados e no “treinamento” da máquina para que ela aprenda e possa futuramente usar aquilo que aprendeu ao trabalhar com novos dados.
Já o não supervisionado, se baseia no deep learning e não envolve a participação humana.
Como o foco do artigo não são os algoritmos, não vou entrar em detalhes. Mas existem vários trabalhos e sites bem legais que você pode visitar caso tenha se interessado por essa área.
Os resultados do uso desses algoritmos podem levar à diversas aplicações, em diversas áreas e exercer enormes impactos sobretudo na tomada de decisão.
A seguir, vamos comentar um trabalho super interessante que eu (Ricardo Giuliani) e Leonardo Viera estamos desenvolvendo, sob orientação da professora Vânia Bogorny, do Departamento de Informática e Estatística da UFSC, no atual cenário que estamos vivenciando.
O PET na Pandemia do Coronavírus
Motivação
Estamos vivendo em um momento muito triste da história em que muitas pessoas estão nos deixando. São parentes, amigos ou conhecidos vencidos por um inimigo invisível que se alastrou mundo a fora em uma velocidade incrivelmente rápida.
Frente ao avanço do Covid-19, nos vimos totalmente despreparados para enfrentar esse vírus prontamente. Seja pelo quesito “fator novidade”, demora na adoção de medidas para conter a pandemia ou pelo simples fato de que alguns países possuem “líderes” completamente despreparados (¯\_(ツ)_/¯ ), é certo que a falta de dados e informações prévias contribuiu bastante para a expansão da pandemia.
Trabalho
A primeira etapa do trabalho é construir um grande banco de dados, contendo diversas informações sobre os estados e municípios brasileiros.
Além de coletarmos o número de casos confirmados, de óbitos e de pessoas recuperadas da doença, estamos coletando informações sobre o índice de isolamento social, a quantidade de leitos disponíveis, dados sobre o clima e as características da cidades como o IDH, o PIB, o tamanho da população e a densidade demográfica.
Com esses dados, estamos interessados em determinar se existe alguma relação entre eles. Ou seja, se um determinado dado tem alguma influencia ou não na quantidade de pessoas infectadas e na quantidade de óbitos.
Também iremos coletar o genoma do vírus de pessoas infectadas, com o apoio do professor Glauber Wagner, do departamento de Microbiologia, Imunologia e Parasitologia da UFSC, para encontrar possíveis mutações e a relação com sintomas e letalidade.
E o Machine Learning?
Após a coleta desses dados, nosso estudo irá se voltar para a aplicação de algoritmos de machine learning. Em um primeiro momento, iremos usar o K-Mean, um algoritimo do tipo não supervisionado.
Com ele, queremos encontrar grupos (ou clusters) nos nossos dados. Por grupo, entende-se dados que estão próximos entre si, ou seja, que apresentam alguma similaridade. O K de K-Mean representa o número de clusters que iremos determinar futuramente e mean significa “média” em inglês.
Esse algoritmo se baseia na distância euclidiana de cada dado em relação aos K clusters. Aqui você pode obter informações completas e detalhadas desse algoritmo.
Com esse algoritimo, esperamos encontrar padrões nos dados e, assim, toda vez que inserirmos novos dados em nosso banco de dados, com o machine learning, eles serão agrupados com os dados mais parecidos. Isso nos permitirá predizer e prever informações importantes.
Dessa forma, ao interpretar os resultados, poderemos ter um entendimento maior sobre o comportamento da pandemia no nosso país.
Conclusões
Como conta a história, sabemos que esta pandemia não é a primeira e também não será a última.
Nosso estudo pode ter uma grande contribuição para a sociedade futuramente, pois com esses dados e com técnicas de machine learning utilizadas, teremos conhecimentos necessários para traçar estratégias mais efetivas e rápidas para o enfrentamento de novas doenças e, assim, evitar a perda de milhares de vidas.